Introduction
Lors de la première partie de cette thèse, nous avons abordé l’écriture en son sens le plus large et montré que l’écriture, en tant que phénomène distribué producteur de sens, est avant tout une affaire de médiations (Vitali-Rosati & Larrue, 2019). L’écriture est ainsi distribuée à la fois dans toute une infrastructure sociale (Denis & Pontille, 2012), mais également dans toute une infrastructure technique (Paveau, 2015), puisque c’est grâce aux protocoles de communication (Galloway, 2004), aux formats (Mourat, 2020) et à toute une infrastructure matérielle que les informations circulent dans un dispositif de communication (McLuhan, 2017; Shannon, 1948). Dans cette thèse, nous ne nous intéressons pas à la dimension sociale de ces interactions, mais nous focalisons notre attention sur la dimension technique de ces médiations, à l’instar de la proposition d’Hutchins dans sa version distribuée de la cognition que nous avons abordée dans le premier chapitre (Hutchins, 1995). En poursuivant dans cette direction, nous avons laissé de côté les écrits d’Hadot sur Marc Aurèle et les marins de l’USS Palau pour nous concentrer, dans le deuxième chapitre, sur les environnements d’écriture numérique au coeur de notre objet d’étude. Dans le deuxième chapitre, nous nous sommes intéressés aux couches les plus basses de l’infrastructure numérique avec la partie matérielle comme point de départ, ainsi qu’à la modélisation du texte dans les couches les plus hautes du numérique. Cet aperçu de l’histoire du hardware et de son fonctionnement nous a permis de montrer que l’abstraction nécessaire à l’interopérabilité des modes d’écriture en environnement numérique n’est pas un fait acquis depuis les débuts de l’informatique. Au contraire, il aura fallu plusieurs décennies de progrès et de perfectionnements pour atteindre cette forme presque agnostique de l’écriture vis-à-vis du matériel, un fait frappant qui démultiplie les possibilités de communication en faisant abstraction du hardware, comme si sa dimension matérielle devenait insignifiante. L’essor des softwares dans les années 1970 et 1980, suite à la miniaturisation des composants électroniques des ordinateurs, notamment les micro-processeurs, engendre un empilement de couches entre la partie matérielle et l’utilisateur. En s’éloignant de plus en plus de la machine et de son langage binaire, chaque couche occasionne un niveau supplémentaire d’abstraction matérielle jusqu’au point où l’on ne considère plus le choix d’un matériel comme relativement important dans l’exécution d’un programme. Un élément capital commun à toutes ces couches est le formatage des informations: quel que soit le niveau où l’on se trouve entre l’utilisateur et la machine, les informations doivent être formatées pour être interprétées, de la sémantique formelle dans un format à l’encodage en ASCII ou Unicode pour devenir calculable. Que l’on soit proche de l’utilisateur ou de la machine, il est nécessaire que ces deux partis puissent comprendre l’information qui leur est donnée à lire1. Si aux deux extrêmes de ce dispositif nous retrouvons le langage naturel et le langage machine, l’ajout de médiations au moyen des logiciels permet d’explorer des étapes entre ces deux pôles et donne lieu à des documents à la fois traitables par la machine et compréhensibles par l’être humain. Afin de rendre cela possible, il était nécessaire de désambiguïser le langage naturel pour décrire formellement et explicitement un élément structurel d’un document. C’est à cet endroit qu’interviennent les normes et les formats, notamment dans le cas de l’écriture. Cet espace entre le langage naturel et le langage machine où le texte transite d’une forme graphique (affichée à l’écran, que le texte soit stylé ou structuré avec des balises) à un formatage, et ceci jusqu’à l’étape d’encodage, relève du champ herméneutique, c’est-à-dire d’un espace où les caractères ont encore une signification. Au-delà de l’encodage, lorsque les caractères deviennent des chiffres, ils quittent cette dimension herméneutique pour celle du calcul et perdent leur sens (Bachimont, 2022; Turing, 1936). La dimension herméneutique devient d’une importance capitale puisque, grâce à la définition de modèles textuels riches et précis, les instructions données pour les calculs peuvent être affinées et enrichir le sens qu’ils produisent.
Sans cette couche herméneutique formatée, comment définissons-nous un titre ? de quel niveau s’agit-il ? un titre en est-il un parce que la taille de la police est plus élevée par rapport à celle d’un paragraphe ? La structuration des contenus dans ces couches intermédiaires apparaît alors comme un enjeu crucial et cela dès la fin des années 1970 avec les premiers logiciels de traitement de texte tel qu’Electric Pencil2. La structuration des contenus fera l’objet de plusieurs spécifications et de formats différents depuis cette période et jusqu’à nos jours, donnant ainsi naissance à des standards comme SGML, HTML, JSON ou XML. Chaque format est adossé à un ensemble de règles dont la finalité est d’expliciter le comportement des éléments structurels d’un document3. En un sens, il apparaît alors fondamental pour chaque environnement d’écriture numérique de se doter de la capacité de traiter une ou plusieurs modélisations du texte, phénomène que nous abordons dans cette deuxième partie de la thèse.
Dans cette partie, nous nous intéressons à la phase de «production des documents», c’est-à-dire à la partie de l’environnement d’écriture où l’on modélise le texte une première fois4. Nous nous intéressons donc aux couches les plus hautes des environnements d’écritures numériques, celles au plus proche de l’utilisateur. Puisqu’il est difficile d’être exhaustif dans une analyse de tous les environnements d’écriture numérique et de toutes les modélisations possibles – ils étaient quelque 300 environnements rien qu’au début des années 1980 (Bergin, 2006a) –, nous nous focaliserons sur un nombre très restreint de ces environnements pour n’évoquer que les plus pertinents dans le cadre de cette étude. Pour être en accord avec notre approche méthodologique annoncée au premier chapitre, nous nous focalisons uniquement sur des cas concrets d’écriture en sélectionnant des environnements particuliers. Dans ce chapitre, nous nous intéressons à l’environnement Microsoft Word (MSWord) utilisé pour l’écriture des sources du livre Contribution numérique: cultures et savoirs5 publié aux Ateliers de sens public en 2024 (Severo & Delannay, 2024).
Cet ouvrage, Contribution numérique, restitue les présentations faites durant le forum du même nom qui s’est tenu en juillet 2022. Ce forum, organisé dans le cadre du projet ANR COLLABORA, a réuni des citoyens et des institutions culturelles avec un double objectif : d’une part marquer la conclusion d’un projet de recherche menée pendant trois ans sur les diverses formes de contribution numérique dans les domaines culturels et du savoir; d’autre part, inaugurer un mouvement de dialogue plaçant les professionnels au centre de la réflexion autour de la contribution numérique. Cet ouvrage restitue le contenu des échanges de cette rencontre, structurés en trois axes, reflétant les trois thèmes autour desquels s’est articulée la discussion du forum: les données, les partenaires et les contributeurs. À l’intérieur de ce livre sont présentés les retours d’expériences de divers acteurs de terrain concernant les expérimentations de contribution numérique réalisées dans le cadre de leurs missions. C’est avec Marta Severo, en sa qualité de coordinatrice et porteuse du projet de recherche sur les plateformes culturelles contributives, que nous avons dirigé l’édition de cet ouvrage. N’ayant participé ni au forum, ni à la recherche durant les années qui ont précédé cet événement, cette posture a été pour moi l’occasion d’être en contact à la fois avec les auteurs, mais aussi avec la structure éditoriale, les Ateliers de sens public, me donnant ainsi la possibilité de participer, de contribuer et de comprendre tous les choix éditoriaux réalisés pour cette publication. J’ai également participé à la conception de l’ouvrage aux côtés d’Hélène Beauchef, éditrice pour les Ateliers de sens public, et David Larlet, développeur principal du Pressoir. Ensemble, nous avons déployé la chaîne éditoriale Le Pressoir6 pour produire les différentes versions du livre: imprimé, PDF, ePUB, HTML (web). Ainsi, notre connaissance des conditions de réalisation de ce livre en font un objet pertinent à étudier dans le cadre de notre recherche, puisque nous sommes passés à travers toutes les étapes de la production des documents jusqu’à leur diffusion. Pour ce chapitre, nous ne nous intéressons pas à la totalité de la chaîne éditoriale et nous gardons pour le cinquième chapitre les transformations des sources opérées par Le Pressoir. Ainsi, pour ce chapitre, nous nous focalisons sur la production des textes dans leur environnement d’écriture, c’est-à-dire un des environnements utilisés par les contributeurs du livre.
Pour écrire les textes de cet ouvrage, le logiciel Microsoft Word (MSWord) a majoritairement été employé par les auteurs. MSWord est un environnement particulièrement intéressant pour notre étude, car il a traversé quasiment la totalité de l’histoire des logiciels de traitement de texte depuis sa mise sur le marché en 1983. Ce logiciel s’est imposé sur le marché depuis les années 1990 et n’a jamais été détrôné depuis cette période, malgré la présence de plusieurs centaines d’alternatives. Tandis que le succès des logiciels est très éphémère, car tous les environnements évoluent et sont de plus en plus performants, tandis que le succès des prédécesseurs de MSWord ne dure tout au plus qu’une poignée d’années (Bergin, 2006b), comment se fait-il qu’un environnement tel que MSWord reste un des outils les plus utilisés plus de 40ans après sa mise sur le marché? Pour le formuler différemment, quel est le sens produit par l’environnement MSWord pour qu’il soit d’actualité pendant une quarantaine d’années malgré des changements majeurs dans les modes d’écriture comme l’écriture collaborative synchrone? Est-ce que la production du sens dans l’environnement MSWord répond-il à la majorité des besoins en écriture?
Notre hypothèse est que le sens produit par le logiciel de traitement de texte MSWord est construit à partir des choix opérés tout au long des développements de cet environnement. Cette construction du sens n’est donc pas décorrélée de son histoire. En se positionnant dans le paradigme WYSIWYG, MSWord se tient ainsi à la frontière entre une régime graphique et régime formel: d’un côté se tient le texte affiché à l’écran, tel qu’il pourrait se présenter sur une page, et de l’autre se trouve le texte modélisé, formaté dans sa forme prête à être calculée. Il y a une friction entre ces deux paradigmes que l’environnement tente de résoudre par la structuration graphique des informations. Cette friction, Dehut la nomme «pensée traitement de texte» (Dehut, 2023, p. 305). Hérité du modèle de l’imprimerie et de la machine à écrire, la page se retrouve alors au centre de cet environnement et intervient comme une tentative de médiation entre les régimes graphiques et formels. En calquant son modèle sur celui de l’imprimé, MSWord est un environnement où l’on peut alors choisir de décrire et de structurer des éléments dans un document soit selon un sens graphique en prévision d’une impression directe, soit selon un sens plus formel et explicite en appliquant des styles graphiques aux contenus. Cependant, du fait de la structuration graphique des contenus coincée dans une page, MSWord est forcément plus limité en termes d’expression que ne le serait un document en texte brut, comme un document XML adossé à un schéma TEI avec des attributs, des propriétés, etc. Cet élément qui a fait le succès de MSWord dans les années 1980, l’interface graphique, est resté au coeur des usages et du sens que produit le logiciel. Ce n’est pas l’interface en tant que représentation graphique qui compte mais ce qu’elle fait: elle permet aux utilisateurs d’osciller entre une forme et un format (Bachimont, 2022) selon les besoins, c’est-à-dire de produire du sens qui réfère soit à une littératie de l’imprimé soit à une littératie numérique. Cet effet, en reprenant les termes de Dehut, est la pensée traitement de texte.
La démonstration de cette hypothèse est réalisée en trois parties. Dans une première partie, nous montrons les frictions qu’il existe entre ces deux états dans les documents sources de l’ouvrage Contribution numérique. La méthodologie mise en oeuvre est empruntée à Roig et Ribera (2021) qui décompressent les documents produits par le logiciel de traitement de texte pour les analyser7. En comparant deux formes que peuvent prendre ces documents, à savoir la forme graphique dans une interface de traitement de texte et la forme décompressée en XML8, nous mettons en lumière les différences de structuration de l’information qui peuvent exister entre les deux modèles. Pour lire la deuxième forme de ces textes, nous nous sommes appuyés sur la documentation du modèle textuel de MSWord afin de déterminer avec précision les définitions des concepts structurels mobilisés, par exemple la définition du concept de paragraphe que Microsoft implémente dans MSWord. Pour expliquer les choix qui ont mené à ces définitions, nous revenons dans une deuxième partie sur l’histoire des logiciels de traitement de texte, notamment à partir des travaux de Matthew Kirschenbaum et ceux de Tim Bergin, afin de contextualiser l’arrivée de MSWord sur le marché du logiciel ainsi que le passage d’un mode WYSIWYM à celui du WYSIWYG avec l’arrivée des interfaces graphiques. Dans une troisième partie, nous nous concentrons sur un des tournants majeurs de l’histoire des traitements de texte: l’intégration du format XML entre 2003 et 2007 en tant que format pivot interopérable des traitements de texte. Il s’agit d’une période cruciale pour Microsoft et MSWord puisque pour la version de la suite de logiciels Office 2007, Microsoft prend la décision de modifier son format de référence et transforme l’iconique DOC en DOCX et change, par cette action, toute la modélisation des contenus dans les documents que le logiciel produit. Ce changement de modélisation nous intéresse particulièrement puisqu’il s’agit du modèle que nous analysons dans les sources de Contribution numérique pour comprendre les différences de sens qu’il y a entre les modèles de texte graphique et computationnel. Nous concluons sur les modalités de production du sens dans l’environnement MSWord pour les textes de l’ouvrage Contribution numérique.
Du texte traité au texte brut
Ci-dessous se trouve une capture d’un fragment de texte extrait du document envoyé par l’un des auteurs du livre Contribution numériques.

Quel sens est accordé à ce fragment de texte? Si l’on se réfère uniquement à ce qui est affiché à l’écran, c’est-à-dire depuis le paradigme de la page et de la raison graphique de Goody (1979), le sens de cet extrait de texte est limpide: il s’agit du mot introduction qu’un lecteur pourra interpréter comme le titre au tout début d’un texte signifiant que le contenu est introduit par le texte qui suit ce titre.
Pour autant, est-ce que cette phrase correspond à ce qui est inscrit sur le document? Si l’on change de représentation pour celle en texte brut en décompressant le fichier au format DOCX9, voici ce que l’on obtient:
<w:p>
<w:pPr>
<w:pStyle w:val="Normal" />
<w:rPr>
<w:b />
<w:b />
<w:bCs />
</w:rPr>
</w:pPr>
<w:r>
<w:rPr>
<w:b />
<w:bCs />
</w:rPr>
<w:t>Introduction</w:t>
</w:r>
</w:p>Les douze caractères compris dans l’image de l’extrait représentent dix-sept lignes au format WordprocessingML (l’application de XML a l’environnement MSWord10) pour décrire l’élément structurel qu’est le paragraphe <w:p>11.
En navigant dans la documentation de WordprocessingML, nous pouvons lire ce qui est inscrit ci-dessus. Tout d’abord, il y a le w: que l’on retrouve dans toutes les balises de WordprocessingML, correspond au nom de domaine du modèle de document. Ensuite viennent trois éléments centraux du modèle que l’on désigne par des minuscules. Ces éléments en minuscule dans les balises de WordprocessingML ont tous une signification : le p signifie un paragraphe, le r signifie une séquence à exécuter et le t correspond à une plage de texte. La lecture de ce mot, Introduction, se fait alors comme suit. Tout d’abord, la première balise <w:p> nous renvoie à un élément de type paragraphe. Au premier niveau à l’intérieur de celle-ci se trouve une balise <w:pPr> contenant les propriétés de ce paragraphe. La première balise enfant <w:pStyle w:val="Normal" /> de cette déclaration des propriétés indique que le style appliqué au paragraphe a pour valeur "Normal", ce qui indique le niveau de texte d’un paragraphe12 dans le modèle de document de WordprocessingML. Ensuite, trois balises nous indiquent des styles à appliquer au paragraphe, deux fois <w:b /> pour appliquer du gras et une fois <w:bCs /> pour appliquer du gras aux scripts complexes13 Ces propriétés ne sont pas directement exécutées puisqu’elles sont déclarées dans les propriétés du paragraphe et non pas celles du texte. Pour la partie relative au texte inscrit par l’auteur, il faut se rendre au niveau de la deuxième balise enfant du paragraphe, <w:r>, une balise contenant une séquence à exécuter. Cette balise contient deux balises enfants, la première étant la balise <w:rPr>. La balise <w:rPr> exécute les propriétés décrites dans les balises qu’elle contient, <w:bCs /> et <w:b />, et les appliques à la balise contenant le texte, <w:t>14.
Cette lecture très linéaire de la modélisation de cet extrait est perturbante à plusieurs égards. D’abord, la notion de paragraphe ne réfère pas à quelque chose de visible, mais plutôt à une forme de conteneur ou de bloc et n’est plus en rapport avec le paragraphe tel que nous le manipulons usuellement. Ensuite, on observe une déclaration du style en gras appliqué à la fois au paragraphe et au texte qu’il contient, alors que nous pourrions nous attendre à voir un titre pour structurer ce mot «Introduction». Puisque le paragraphe n’est pas un élément visible, pourquoi lui adosser des styles en gras (complexe ou non), alors que le texte est encapsulé dans la balise <w:t>? Cette question ne trouvera pas de réponse immédiate, car il nous semble évident que l’auteur n’a pas souhaité structurer le texte de cette manière. Il est plus probable qu’il ait surligné la chaîne de caractères Introduction, puis cliqué sur le bouton bold pour appliquer ce style aux caractères surlignés.
La structuration des éléments les plus simples d’un document, un titre, un paragraphe, une emphase, est déjà complexe. Par exemple, les concepts de paragraphe et de subdivision du texte y sont distincts, tandis que dans d’autres modélisations d’un document, comme en HTML, l’élément paragraphe <p> contient à la fois le texte et son niveau hiérarchique. En se référant à la documentation du paragraphe dans WordprocessingML15, le paragraphe correspond à un espace dans lequel tout un ensemble d’informations peuvent y être contenues. Ces informations peuvent être de quatre types différents: des propriétés, des annotations (des commentaires, des révisions, des marque-pages,), des éléments personnalisés et, enfin, des éléments exécutables comme du texte, des hyperliens, des champs, etc. Autre fait troublant, la structuration de cette information en tant que paragraphe n’est pas une erreur de la part de l’auteur. Le concept de titre n’existe pas en tant qu’élément balise dans le modèle WordprocessingML, comme on le retrouve en HTML (avec les balises sur 6 niveaux allant de<h1> à <h6>), mais est une propriété de l’élément paragraphe. Que l’auteur saisisse un paragraphe “normal” ou clique sur un style pour déclarer un titre, ce n’est que la valeur affectée aux propriétés du paragraphe qui change: pour déclarer un titre de niveau 2, la propriété du paragraphe <w:pStyle w:val="Normal" /> serait remplacée par <w:pStyle w:val="Titre2" />. Dans tous les cas, pour cette modélisation du document, un titre doit être interprété comme un paragraphe. Le paragraphe n’est alors plus un délimiteur d’une chaîne de caractères pouvant contenir des objets comme des emphases ou des hyperliens et que l’on associe à un élément plus important dans la hiérarchie des informations (comme un titre), mais comme un conteneur parent de toute une modélisation relativement complexe dans laquelle peuvent s’entremêler des commentaires avec du texte ou des éléments de révision.
Par exemple, dans l’exemple ci-dessous, nous avons affaire à un paragraphe avec pour valeur “titre de niveau 3” et comportant un commentaire dans lequel nous avons proposé une légère modification du titre en ajoutant le mot “Conclusion :” au début du titre et en modifiant le “V” majuscule pour une minuscule16:
<w:p>
<w:pPr>
<w:pStyle w:val="Heading3" />
<w:rPr>
<w:b />
<w:b />
<w:bCs />
</w:rPr>
</w:pPr>
<w:ins w:id="0" w:author="Roch Delannay" w:date="2023-03-17T10:20:21Z">
<w:r>
<w:rPr></w:rPr>
<w:t xml:space="preserve">Conclusion : </w:t>
</w:r>
</w:ins>
<w:ins w:id="1" w:author="Roch Delannay" w:date="2023-03-17T10:42:40Z">
<w:r>
<w:rPr></w:rPr>
<w:t>v</w:t>
</w:r>
</w:ins>
<w:del w:id="2" w:author="Roch Delannay" w:date="2023-03-17T10:42:40Z">
<w:commentRangeStart w:id="0" />
<w:r>
<w:rPr>
<w:b />
<w:bCs />
</w:rPr>
<w:delText>V</w:delText>
</w:r>
</w:del>
<w:r>
<w:rPr>
<w:b />
<w:bCs />
</w:rPr>
<w:t>ers une méthodologie de conception des plateformes culturelles contributives</w:t>
</w:r>
<w:commentRangeEnd w:id="0" />
<w:r>
<w:commentReference w:id="0" />
</w:r>
<w:r>
<w:rPr>
<w:b />
<w:bCs />
</w:rPr>
</w:r>
</w:p>Ce commentaire, qui est en réalité une proposition de révision, est associée à un autre commentaire par un identifiant unique w:id="0" se trouvant dans la colonne de droite de l’interface du logiciel, en dehors de la page. On le retrouve également dans un autre document au format XML, différent de celui contenant le texte affiché sur la page, sous la forme suivante:
<w:comment w:id="0" w:author="Roch Delannay" w:date="2023-03-14T16:28:48Z" w:initials="">
<w:p>
<w:r>
<w:rPr>
<w:rFonts w:ascii="Calibri" w:hAnsi="Calibri" w:eastAsia="Tahoma" w:cs="Tahoma" />
<w:sz w:val="24" />
<w:szCs w:val="24" />
<w:lang w:val="en-US" w:eastAsia="en-US" w:bidi="en-US" />
</w:rPr>
<w:t>proposition : ajout du terme Conclusion dans le titre pour harmoniser avec les autres textes</w:t>
</w:r>
</w:p>
</w:comment>Dans WordprocessingML, le commentaire est une notion ambiguë puisque, pour une même action dans l’interface, on la retrouve dans deux documents différents: à la fois dans le document principal comme une insertion dans un paragraphe en tant que sous élément de l’élément paragraphe, et à la fois dans un autre document dédiée comments.xml en tant que conteneur <w:comment> de l’élément paragraphe <w:p>. C’est donc une notion qui déborde du document principal et qui comporte des éléments qui seront imprimés et d’autres non. Si la notion de WYSIWYG nous montre dans son interface ce que l’on va obtenir lors de l’impression en insérant dans la page ce qui doit être imprimé et à l’extérieur de la page ce qui ne doit pas l’être, la définition de l’élément commentaire n’est pas aussi franche puisqu’elle déborde dans ces deux facettes du document, à la fois comme élément que l’on va imprimer et comme élément informationnel pour l’utilisateur dans son interface.


Nous avons vu deux exemples différents de la modélisation des documents dans MSWord. Le premier correspond à une confusion entre la structuration graphique des informations et l’application de styles aux informations dans le texte, tandis que le second révèle des ambiguïtés structurelles des informations avec la notion de commentaire qui est appliquée à plusieurs espaces du document alors qu’il ne s’agit que d’une seule action du côté utilisateur. Un troisième exemple met en évidence la non-structuration de certains éléments puisque ces notions n’existent pas dans le modèle de document WordprocessingML.
Toute modélisation de document est confrontée à une limite: les modèles définissent ce que l’on peut décrire ou non, sans jamais être totalement exhaustif (c’est aussi pour cette raison que l’on crée des modèles différents). Or, par exemple, la notion de résumé ou d’abstract, si importante dans le monde éditorial, n’existe pas dans le schéma de MSWord. C’est une notion absente qu’un auteur ne pourra pas mobiliser pour décrire formellement qu’un ensemble de caractères est un résumé. Dans le cas de l’ouvrage Contribution numérique, le résumé fait partie des éléments demandés aux auteurs. Chaque auteur devait fournir un document contenant un ensemble de métadonnées dont un résumé. Dans un des textes, le résumé est déclaré comme suit:

En lisant ce texte depuis l’interface du logiciel, nous pouvons associer le paragraphe au titre et comprendre qu’il s’agit bien là d’un résumé. Cependant si nous observons la structure des informations dans le document, on remarque qu’il n’y a pas d’élément résumé, mais seulement des paragraphes, un avec une valeur titre de niveau 2 et l’autre comportant du texte. L’extrait ci-dessous a été tronqué pour mettre en évidence seulement les balises <w:p>.
<w:p w14:paraId="5A04E37F" w14:textId="77777777" w:rsidR="00A96967" w:rsidRDefault="004D40F9">
<w:pPr>
<w:pStyle w:val="Titre2" />
</w:pPr>
<w:r>
<w:t xml:space="preserve">Résumé </w:t>
</w:r>
</w:p>
<w:p w14:paraId="0898529C" w14:textId="142DF421" w:rsidR="00A96967" w:rsidRDefault="004D40F9">
<w:r>
<w:t>Le projet de transcription scientifique collaborative «
</w:t>
</w:r>Cette structuration du résumé et des autres métadonnées est valable pour absolument tous les textes de Contribution numérique. Puisque l’élément résumé n’est pas descriptible dans le modèle de MSWord, les auteurs s’en remettent à une raison graphique pour écrire ces éléments. Sans cela, il ne serait pas possible d’écrire un résumé. Cependant, selon le référentiel computationnel, le résumé n’a pas de définition, mais est bricolé avec celle de deux paragraphes, un titre et du texte, rédigés au début du document. Si l’on s’appuie strictement sur ce référentiel, alors le résumé n’existe pas.
À travers ces trois exemples, on peut en déduire qu’il y a donc une différence notable entre l’interprétation graphique du texte et l’interprétation structurelle du document. C’est précisément à cet endroit que l’on observe une friction entre la forme imprimée et le texte formaté. Que ce soit la confusion entre un titre et un paragraphe tiré de notre premier exemple, ou encore l’ambiguïté du commentaire dans le deuxième exemple, ou bien le fait d’écrire et de bricoler des éléments structurels qui ne sont pas descriptibles comme nous venons de le voir avec le résumé; ces exemples ne sont pas des cas isolés d’une structuration des contenus difficile à lire à l’intérieur d´un document issu de MSWord. Ce phénomène est récurrent, et pas seulement pour la structuration des éléments les plus simples comme un titre, un paragraphe ou un commentaire; c’est également le cas pour des éléments plus complexes tels que des appareils critiques pour l’écriture en philologie17. De plus, pour les éléments descriptibles dans le modèle de MSWord, leur structuration est verbeuse et ambiguë si on ne la considère que depuis le texte brut, contrairement à d’autres formats comme le Markdown ou la Text Encoding Initiative (TEI) en XML pour lesquels les règles d’écriture sont plus explicites. Ce fait rendrait la tâche d’écrire un document au format DOCX en dehors d’une interface WYSIWYG très ardue18. Néanmoins, si l’on reste dans la perspective de créer un document à imprimer, la lecture de la structure des éléments devient secondaire au profit de l’interprétation graphique du document, puisque la définition des éléments structurels de WordprocessingML se rapproche finalement plus des définitions des objets issus de l’imprimerie.
Histoire du traitement de texte
Pour comprendre les choix de modélisation d’un texte dans MSWord ainsi que cette pensée du traitement de texte, il convient de rappeler l’histoire de ce logiciel. Pour rappeler l’histoire de Microsoft Word, il nous faut également rappeler l’histoire du traitement de texte, car celle de MSWord s’inscrit plus largement dans la course aux développements des logiciels de traitement de texte que l’on observe tout au long des années 1980. Malgré le fait qu’aujourd’hui nous ne remettons plus en cause la suprématie de ce logiciel, MSWord n’apparaît pas comme une solution tout à fait innovante en 1983 et s’inscrit, au contraire, dans toute une bataille entre logiciels dont l’objectif ultime est le monopole du traitement de texte. Bien avant la fin des années 1970, c’est-à-dire avant que ces logiciels ne fassent leur apparition, écrire un texte avec un ordinateur n’est pas quelque chose que l’on pratique quotidiennement, c’est d’ailleurs quelque chose que l’on pourrait qualifier d’impensable. Les ordinateurs, même lorsqu’ils commencent à être miniaturisés, sont d’abord conçus et utilisés en tant que machines à calculer et non pas comme des machines à écrire, comme c’était déjà le cas de leurs prédécesseurs de plus grande envergure, tel que l’un des premiers ordinateurs, baptisé le Harvard Mark I dont le nom officiel donné par IBM est Automatic Sequence Controlled Calculator (ASCC)19. D’ailleurs, les machines à écrire sont toujours en vogue à cette période20 et c’est bien sur ces dernières que les informaticien·ne·s rédigent des documents, que ce soit de la documentation technique ou autre papier que l’on doit faire circuler ou publier.
Seulement un problème commence à se poser alors que les ordinateurs personnels se répandent chez les particuliers pendant que les fabricants de logiciels écrivent le code source des logiciels sur une machine et leur documentation sur une autre. La machine à écrire présente un inconvénient majeur, contrairement à l’ordinateur: elle n’offre pas de moyen d’éditer le texte une fois qu’il est tapé. Créer une documentation pour un logiciel devient très vite une activité fastidieuse, car il faut adapter la documentation pour chaque combinaison de matériel disponible, et selon tout un ensemble de caractéristiques du hardware comme le processeur utilisé ou encore la quantité de mémoire disponible dans l’ordinateur. Les technologies de reproduction des documents produits avec des machines à écrire – l’utilisation du papier carbone couplé à l’emploi d’une polycopieuse – ne sont plus fonctionnelles dès lors qu’il faut modifier le contenu de la documentation. Dans un ordinateur, au contraire, les données sont accessibles en écriture. On peut donc les éditer, mais on peut également les dupliquer. Grâce à ces fonctionnalités, il est possible de maintenir plusieurs versions d’une documentation d’un logiciel adaptées aux différentes configurations matérielles des ordinateurs.
C’est ainsi qu’est développée l’idée de pouvoir écrire la documentation d’un logiciel dans le même environnement que son code source (Bergin, 2006a). C’est dans cette situation que Michael Shrayer développe en 1976 le tout premier logiciel de traitement de texte grand public: Electric Pencil21.
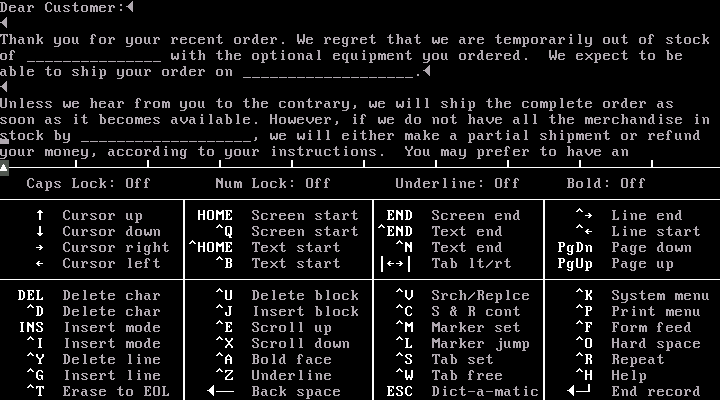
Malgré le fait que les fonctionnalités d’Electric Pencil paraissent limitées et minimales pour tout éditeur de texte contemporain, elles influenceront pourtant les logiciels qui suivirent, WordStar, WordPerfect, etc. Comme nous pouvons le lire dans la documentation du logiciel, nous retrouvons parmi ces fonctionnalités l’affichage du texte à l’écran, l’insertion de texte à n’importe quel endroit d’un document, les fonctions de recherche et de remplacement, la numérotation automatique des pages et, bien évidemment, la fonctionnalité d’impression du document. À l’époque d’Electric Pencil, le traitement de texte est encore dans le paradigme WYSIWYM et repose sur la saisie de commandes et de fonctions propres à ce logiciel pour structurer les informations en vue d’obtenir un texte mis en page lors de l’impression. Dans cet environnement, l’utilisateur n’a pas à se soucier des marges sur les côtés ou du placement du texte dans la page, c’est Electric Pencil qui s’en occupe. Comme nous le voyons ci-dessus sur la capture d’écran 2, l’écran est découpé en deux parties: le texte est sur la partie supérieure tandis que la partie inférieure rappelle les commandes utilisables pour en gérer l’insertion dans le texte.
Donald Knuth, professeur en informatique à l’université de Stanford, rencontre une problématique similaire dans les années 1970. Insatisfait des épreuves que sa maison d’édition lui envoie pour la seconde édition de The Art of Computer Programming (Knuth, 1997), il décide de développer TeX, un logiciel de composition typographique, et publie une première version de celui-ci en 1978. 46 années plus tard, la communauté de TeX et de LaTeX continue de développer et améliorer tout l’environnement de composition de texte. Il s’agit là d’un des environnements d’écriture connaissant la plus longue longévité de l’histoire des environnements d’écriture numérique. À l’instar d’Electric Pencil, TeX fonctionne sur un mode WYSIWYM, sans autre interface graphique qu’une fenêtre de terminal. La composition du texte repose sur l’emploi de commandes que l’on écrit en texte brut à l’intérieur du document – de façon analogue au balisage d’un texte –, puis le programme TeX est en charge d’interpréter ces commandes et de compiler le document à imprimer à partir de ces dernières. Ces commandes peuvent être divisées en deux types de commandes. Il y a d’abord les fonctions primitives, initialement au nombre de 300, puis Knuth y ajoute des macros que l’on range sous l’appellation plain TeX22. Ce sont ces macros qui sont couramment utilisées par les usagers lorsqu’ils écrivent dans l’environnement TeX (et LaTeX). Par la suite, la communauté a développé des milliers de paquets que tout utilisateur de LaTeX peut charger dans son document selon ses besoins. On compte à ce jour 6694 paquets disponibles sur le CTAN, développés par 3033 contributeurs23.
Que l’on soit dans Electric Pencil, TeX, ou encore d’autres environnements de cette même époque tel que EasyWriter24, la conception du document numérique différait de la conception du document imprimé. Le document numérique comportait un ensemble de commandes qu’un logiciel interprétait alors pour effectuer les calculs de mise page du texte en vue de son impression. Sans aperçu à l’écran, il est donc nécessaire d’attendre que le document soit imprimé pour valider ou non la mise en page.
L’approche WYSIWYG, qui offre cette possibilité d’afficher un aperçu de ce à quoi ressemblera le document après impression, apparaît sur le marché des logiciels en 1978 avec le logiciel WordStar, considéré par son concepteur comme le tout premier logiciel de ce type (Rubinstein, 2006). WordStar était l’un des logiciels les plus populaires au début des années 1980, d’ailleurs il est toujours utilisé grâce à des émulateurs MS-DOS, comme en témoigne George R. R. Martin, le célèbre auteur de la saga Le Trône de Fer (Kirschenbaum, 2016, p. 9). WordStar a été vendu à plusieurs millions d’exemplaires partout dans le monde. S’il n’avait pas décliné à cause d’une grave erreur de conception, MicroPro International, l’entreprise qui détenait les droits du logiciel WordStar, aurait peut-être pu développer le concept de pack office que l’on connaît chez Microsoft: «Dès le départ, mon concept était celui d’une suite d’applications de type front office. Elle s’appelait Starburst, et contenait CalcStar, InfoStar, et WordStar: le tableur, la base de données et le traitement de texte25 (Rubinstein, 2006).

Cette interface, aussi rudimentaire fut-elle, était malgré tout la première interface à montrer des éléments à l’écran comme les sauts de page, le gras et l’italique26. En fournissant ce type de fonctionnalité, WordStar avait un atout majeur par rapport à ses concurrents puisqu’il permettait de faire de l’ordinateur un objet fonctionnel et utilisable immédiatement sans qu’aucune compétence en ingénierie ou en informatique ne soit requise (Rubinstein, 2006). Toutefois, le déclin de WordStar est tout aussi fulgurant que sa montée en puissance. Puisque le logiciel initial a été programmé directement en assembleur pour le processeur Intel 8080, le portage sur d’autres systèmes plus moderne a été fastidieux. Au lieu de s’appuyer sur l’existant et de créer un nouveau logiciel compatible avec l’ancien, WordStar2000, le logiciel créé à la suite de WordStar, ne permettait pas de traiter des documents créés avec WordStar (et inversement), causant ainsi la chute de WordStar en 1987 pour laisser la place d’abord à WordPerfect, qui sera leader du marché des logiciels de traitement de texte jusqu’en 1992, lorsque le système d’exploitation Windows deviendra le plus populaire et permettra à Microsoft de dominer ce marché avec son logiciel Microsoft Word.
Microsoft Word a fait sa première apparition en 1983. En 1981, Microsoft embauche Charles Simonyi, un ancien développeur du Palo Alto Research Center (connu sous l’acronyme PARC) de l’entreprise Xerox, pour développer MSWord. Les travaux de Simonyi, tout comme la plupart des recherches effectuées chez Xerox Parc, ont largement été influencés par les travaux de Licklider27, l’ancien directeur de l’ARPA de 1962 à 1964, notamment son article «Man Computer Symbiosis» (Licklider, 1960). Licklider décrit sa vision du futur de l’informatique et des relations humain-machine dans cet article.
Pour Licklider, la relation entre un ordinateur électronique et un être humain est une promesse d’une évolution des modes de pensée. Dans cette relation symbiotique, l’ordinateur devient une aide à la prise de décision dans des systèmes complexes que l’humain ne pourrait réaliser sans son concours. De la même manière, Licklider ne croit pas au dépassement de l’intelligence artificielle sur l’intelligence humaine. Au contraire, il estime qu’avant d’en arriver à une telle situation, les machines et les humains vont «travailler ensemble dans une association intime» pour développer des pensées complexes (Licklider, 1960). La notion de symbiose que convoque l’auteur positionne la machine comme une entité bénéficiaire de cette relation, et pas seulement comme un outil permettant d’étendre les capacités de ce dernier via l’automatisation. Ce bénéfice, que ce soit pour l’humain ou la machine, se trouve justement au niveau de cette pensée. En 1960, lorsque Licklider écrit ces lignes, les ordinateurs ne sont pas encore à la hauteur de cette vision. Aussi, après avoir introduit cette dernière, il dresse une liste des points d’amélioration nécessaires pour l’atteindre: la mémoire numérique, les langages de programmation, l’équipement de gestion des inputs et outputs telle que la reconnaissance vocale, notamment.
Au PARC, Simonyi a travaillé à la mise sur le marché de l’ordinateur personnel Alto, après deux années de développement (Freiberger & Swaine, 2000, p. 326). Alto s’est doté d’un logiciel de traitement de texte, l’éditeur Bravo développé par nul autre que Simonyi comme expérimentation pour son PhD28, le tout premier logiciel de traitement de texte WYSIWYG29. Dans la documentation du logiciel datant de 1979, nous avons trouvé ceci :
Si vous comparez la copie papier de votre document avec l’écran de Bravo, vous verrez que, bien que le texte soit identique, la copie papier comporte plus de mots sur chaque ligne, de sorte que les deux versions sont très différentes. Pour voir à l’écran un fac-similé presque exact de la copie papier, vous pouvez passer la commande
Look hardcopy (note the lower-case h). Vous êtes maintenant en mode copie papier à l’écran. Jusqu’à nouvel ordre, Bravo représentera la version imprimée de votre document aussi fidèlement que possible, en positionnant chaque caractère à l’écran à un demi-point d’écran (environ 0,007 pouce) de sa position dans la copie papier finale.30
Cette partie de la documentation nous laisse penser que le mode hardcopy est ce qui se rapproche le plus d’un mode WYSIWYG où l’affichage du document à l’écran est quasiment conforme avec le document imprimé.
Si WordStar et Bravo sont les premiers outils de traitement de texte WYSIWYG, ils ne sont pas encore dans une interface graphique avec des icônes sur lesquels cliquer pour déclencher une action. C’est le Xerox PARC qui est à l’origine31 de plusieurs avancées en informatique allant dans ce sens: les interfaces graphiques, les icône-boutons, etc., mais ces développements ne seront pas vraiment disponibles sur le marché32. Grâce à Simonyi, MSWord hérite des réalisations du PARC pour ses développements, notamment des résultats obtenus avec le traitement de texte Bravo et les recherches sur les interfaces graphiques.
MSWord n’est pas le logiciel le plus utilisé dès sa sortie, il faudra attendre presque 10 ans pour que ce soit le cas, dès que le logiciel sera intégré au système d’exploitation Windows 3.0 en 1992 (et à son interface graphique). Comme nous l’avons vu, WordStar domine le marché à cette époque-là, suivi par WordPerfect33 jusqu’à ce que MSWord remporte cette course au monopole en 1992 (Bergin, 2006b). L’engouement observé à cette époque pour les traitements de texte et le mode WYSIWYG ne tient pas seulement du fait que l’ordinateur permette d’écrire: l’ordinateur permet d’obtenir un document «parfait»34.
Il y a donc ici un lien très étroit entre l’écriture sur ordinateur et le document que l’on obtient après impression. Ce qualificatif «parfait», fait référence à une forme de «dématérialisation de l’acte d’écriture» car le document, une fois imprimé, ne comporte plus les traces de son écriture, comme s’il n’avait pas d’historique des modifications et avait directement émergé de l’esprit de l’auteur en une seule itération (Kirschenbaum, 2016, p. 36). Cette perfection du document issu du traitement de texte est à mettre en perspective avec le document obtenu avec une machine à écrire. Quel que soit le dispositif utilisé pour écrire — qu’il s’agisse d’une machine à écrire, d’un ordinateur ou d’un stylo —, des erreurs ou coquilles peuvent facilement se glisser dans un document. Toutefois, en dehors de l’ordinateur, les processus de réécriture et de correction des erreurs dans les autres dispositifs laissent souvent des traces visibles dans le document final. Par exemple, une erreur corrigée en bas de page peut laisser une marque discrète sur un document produit avec une machine à écrire, car réécrire toute une page était souvent jugé trop chronophage. En revanche, si les erreurs se situent en haut de page, il était parfois nécessaire de réécrire entièrement le document sur une nouvelle feuille (Kirschenbaum, 2016, p. 34). Et encore, cela ne tient pas compte des conséquences que ces coquilles pouvaient avoir sur les copies carbone du document original. La correction ou la réécriture d’un document a alors un coût économique très élevé, à la fois en temps de travail mais aussi en fournitures. Écrire sur un ordinateur avec un logiciel de traitement de texte a pour effet de diminuer ces coûts et d’obtenir, depuis ce point de vue, des documents «parfaits». La perfection du document numérique a alors un double sens: elle est à la fois économique et gratifiante pour l’auteur. Dans le deux cas de figure, ce qualificatif désigne la copie imprimée du document et pas sa version numérique. La version numérique n’est alors qu’un moyen d’obtenir une version papier (hardcopy) du document. En ce sens, la modélisation du texte et de sa structure n’a que peu d’importance puisque, l’élément qui doit être parfait est le document imprimé. Ainsi, le traitement de texte tel qu’il est conçu dans les années 1970 et 1980 ne considère le traitement du texte en vue de son impression et non pas en vue de l’intégrer dans une chaîne éditoriale numérique plus complexe. Les informations et leur structure ne sont alors pas pensées pour être transformées ou converties en d’autres formats intermédiaires avant leur impression ou publiées sur le web (si nous nous permettons de faire un saut temporel jusque dans les années 1990). Si dans les premières décennies des traitements de texte, le document parfait correspond au document imprimé, est-ce que cette assertion est toujours valide pour les logiciels contemporains ?
De DOC à DOCX
La modélisation des documents telle que nous l’avons observée précédemment est liée au format DOCX et au modèle WordprocessingML, l’application pour MSWord de la norme Office Open XML (ISO 29500). Selon les documents que nous avons pu analyser, les plus vieilles versions du modèle de WordprocessingML employées par les auteurs de Contribution numérique datent de 2012. Cette modélisation des documents est relativement récente sur toute l’existence de ce logiciel et remonte à l’introduction en décembre 2006 de la norme Office Open XML35 alors implémentée dans la version de MSWord de 2007 sous la forme de WordprocessingML. C’est à ce moment que le format DOCX remplace le format historique DOC. Jusqu’à cette date, le format employé par MSWord, DOC, était un format propriétaire impossible à décompresser comme nous venons de le faire avec les documents de Contribution numérique. Ce n’est que lorsque Microsoft opère sa transition vers Office Open XML (OOXML) que le format devient accessible.
Ce changement brusque sur la politique des formats de Microsoft provient du fait de l’émission de directives nationales relatives à des problématiques d’interopérabilité des documents révisables lorsque ceux-ci circulent entre les citoyens et les institutions36. Le format DOC, représentant 90% des parts du marché (Yami et al., 2015), est propriétaire et ne s’exécute que sous MSWord. Il ne peut opérer qu’en silo et requiert que toutes les personnes manipulant des documents produits avec MSWord aient une licence du logiciel pour être en capacité de réviser le document. Microsoft se retrouve alors dans la situation où leur format n’est plus compatible avec les directives en question, puisqu’il ne répond pas aux exigences sur l’interopérabilité. Avec la montée en puissance de la concurrence, notamment la suite de logiciels de bureautique d’OpenOffice, qui s’est alignée depuis 2005 sur la norme OpenDocument Format (ODF)37, Microsoft se retrouve face à un concurrent sérieux qui risque de récupérer le monopole du marché des traitements de texte s’ils n’adaptent pas leur produit.
Parmi les différentes possibilités d’évolution de MSWord, Microsoft fait le choix de créer sa propre norme pour se distinguer de leur concurrent plutôt que d’utiliser la même norme Open Document Format38 En 2015, Yami, Chappert et Mione proposent une étude des stratégies de compétition et de coopération mises en oeuvres par l’entreprise Microsoft auprès du comité de l’AFNOR – représentant de la position française – dans le processus de normalisation d’Open Office XML auprès de l’ISO (Yami et al., 2015). En 2007, une fois que l’ECMA a validé le format comme standard officiel, elle le soumet ensuite à l’ISO pour élaborer une norme internationale par «voie express». Yami et al. nous montrent que le processus de normalisation de ce format n’est pas une affaire banale et, qu’au contraire, elle a fait l’objet de discussions, d’échanges et de votes (pas toujours positif) avant que Office Open XML soit adoubée en tant que norme ISO (International Organization for Standardization). Au-delà de la création d’une norme concurrente, l’ISO a soulevé la contradiction dans l’élaboration d’une nouvelle norme internationale répondant au même besoin que la norme ODF créée quelques mois auparavant. Dans l’article de Yami et al., nous trouvons des extraits de courriels envoyés au moment de l’élaboration de documents pour les enquêtes probatoires dont le contenu est clairement positionné contre l’établissement de cette norme :
(…) Ne t’inquiète pas, ceci a bien été vu et dit hier. Pour info, la réunion d’hier, dont j’étais, a été assez houleuse, Microsoft contestant systématiquement tous les points et tentant de faire rejeter un maximum de commentaires. Plus surprenant, le Président de la commission a tenté à plusieurs reprises d’éliminer des commentaires techniques pertinents qui n’étaient peut-être pas bien rédigés (les règles étant pour le moins floues, pour ma part, si les règles avaient été plus claires j’aurais bâti autrement ma contribution) sous prétexte que lui ne les comprenait pas. Je souhaite bien du plaisir à ceux qui vont travailler aujourd’hui, car vu la situation d’hier, il est clair qu’il n’y a pas consensus, et qu’il parait assez évident que MS devrait retravailler complètement son brouillon, et l’alléger de plein de fatras. Problème, si ceci est fait, il ne resterait sans doute qu’un clone bien proche d’ODF! (…) (Courriel 127) (Yami et al., 2015)
Lors d’un premier vote le 4 septembre 2007, l’assemblée formée à l’ISO, composée de membres provenant de 104 pays différents, vote pour ne pas retenir ce format en tant que norme ISO39 Cinq mois plus tard, du 25 au 29 février 2008, les délégations nationales de 37 pays se sont réunis une deuxième fois pour analyser les 3500 commentaires émis en 2006 sur ce dossier40. Sur ces 5 journées de travail, il est mentionné que le comité n’a pas pu passer en revue la totalité des commentaires, car leur nombre était trop élevé pour un traitement dans un laps de temps aussi court.
Lorsqu’il est apparu qu’il serait impossible de passer toutes les observations en revue, il a été convenu, après discussion, d’une procédure de vote pour statuer sur le reste des modifications proposées. Au total 43 résolutions, impliquant des dispositions ou des groupes de dispositions, ont été acceptées, la plupart d’entre elles à l’unanimité, quelques-unes par voie de consensus, quatre seulement à la majorité simple; quatre ont été refusées.41
Suite à cette deuxième réunion, 87 délégations ayant voté en septembre 2007 ont alors bénéficé d’un mois supplémentaire (jusqu’à mars 2008) pour modifier leur vote initial et ainsi changer l’issue négative de création d’une norme concurrente à ODF42. Le 2 avril 2008, un billet est publié sur le site de l’ISO et confirme l’approbation de la norme 29500 en tant que norme internationale «avec 75% de votes positifs des membres participants du JTC 1 et 14% de votes négatifs sur le total des votes des comités membres nationaux»43. Depuis l’introduction de cette norme internationale, Microsoft s’appuie sur WordprocessingML pour gérer la structuration des informations dans le traitement de texte MSWord.
Ce processus aura mobilisé des centaines de personnes provenant du monde entier, qu’elles soient expertes du domaine ou qu’elles soient des concurrentes. Malgré les avis divergents, la norme soumise par l’ECMA devient une norme internationale sur laquelle des applications de traitement de texte (et des feuilles de calcul, etc.) peuvent être construites. Qu’en est-il de tout ce «fatras» mentionné durant l’élaboration du dossier, ou alors des questions sur les différences entre Open Document Format et Office open XML? Nous relions cette question à celles des ambiguïtés que nous avons relevées dans les exemples de Contribution numérique, comme le fait que les titres soient structurés dans des balises de paragraphe (avec un attribut ayant pour valeur un titre).
Microsoft réalise son schéma XML sur plusieurs années dès la fin des années 1990, et non pas à la hâte en 2005, lorsque la norme ODF est acceptée par OASIS. Microsoft connaît très bien cette technologie. D’ailleurs, malgré qu’ils ne soient pas nommés dans les premiers brouillons des spécifications de XML en 1996, le nom de Jean Paoli, travaillant alors pour Microsoft, apparaît dès août 1997 parmi les éditeurs de ces documents44. Dans ce même document, apparaît également le nom de Jon Bosak travaillant pour Sun Microsystems45, l’entreprise qui a développé la suite OpenOffice avant qu’elle soit rachetée en 2008 par Oracle.
XML a été développé par un groupe de travail XML (connu à l’origine sous le nom de SGML Editorial Review Board) formé sous les auspices du World Wide Web Consortium (W3C) en 1996 et présidé par Jon Bosak de Sun Microsystems […] Cette spécification a été préparée et approuvée pour publication par le W3C XML Working Group (WG). L’approbation de cette spécification ne signifie pas nécessairement que tous les membres du WG ont voté pour cette approbation. Au moment où cette spécification a été approuvée, le WG était composé des membres suivants: Jon Bosak, Sun (Chair); James Clark (Technical Lead); Tim Bray, Textuality and Netscape (XML Co-editor); Jean Paoli, Microsoft (XML Co-editor); C. M. Sperberg-McQueen, U. of Ill. (XML Co-editor); Steve DeRose, INSO; Dave Hollander, HP; Eliot Kimber, Highland; Tom Magliery, NCSA; Eve Maler, ArborText; Murray Maloney, Grif; Peter Sharpe, SoftQuad;46
Microsoft était impliqué dans le développement de la technologie XML depuis ses débuts et a commencé son intégration à la suite Office dès la version de 2003.47. Dans la note de remise aux fabricants en août 2003, nous pouvons y lire que Microsoft se prépare déjà à rendre son environnement interopérable avec d’autres logiciels :
La prise en charge de XML et d’autres normes industrielles permet une communication transparente entre les programmes Microsoft Office et les applications d’éditeurs de logiciels indépendants, et pose les bases de l’ajout de données en temps réel et de services Web pour une valeur commerciale encore plus grande. Les améliorations apportées à Outlook, Exchange, Windows® SharePoint Services et SharePoint Portal Server offrent de nouvelles fonctionnalités qui permettent aux individus, aux équipes et aux organisations de collaborer le plus efficacement possible48.
Quelques semaines plus tard, en octobre 2003, lorsque la nouvelle version de la suite Office est rendue accessible au public, Steve Ballmer, le directeur exécutif de Microsoft à cette époque, s’exprime publiquement dans un communiqué49 dans lequel il prévoit clairement que le futur de la suite Office réside dans l’interconnexion des logiciels entre eux, avec pour objectif d’améliorer la productivité des utilisateurs:
De notre point de vue, il ne s’agit pas d’un tableur et d’un traitement de texte. C’est peut-être là que les gens pensent qu’il a évolué. Nous considérons Microsoft Office comme le fondement de l’ensemble définitif d’outils que nous devons fournir pour améliorer la productivité des travailleurs de l’information. […] Nous avons apporté quelques améliorations en matière de collaboration. Nous avons étendu leurs capacités Internet. Nous avons facilité leur déploiement. Mais c’est vraiment la première génération depuis longtemps où nous avons, je pense, fait avancer de manière significative la frontière de la productivité pour le travailleur de l’information. Le système Microsoft Office 2003 n’est pas seulement un traitement de texte et un tableur. En fait, il ne s’agit même pas d’une simple application côté client. Il s’agit d’une application côté client qui peut parler et exploiter intelligemment l’infrastructure du serveur, les services qui fonctionnent dans le nuage Internet et les solutions qui ont été développées et écrites par nos partenaires ainsi que par les clients finaux qui aident à améliorer l’expérience globale de la productivité pour les gens.50.
Durant les années 1970 et 1980, l’ordinateur et les premières générations de logiciels de traitement de texte ont remplacé la machine à écrire, puis, pendant les années 1990, les interfaces graphiques se sont imposées et ont remplacé les interfaces textuelles. Au tournant du nouveau millénaire, Ballmer met l’accent lors de son discours sur l’interopérabilité des données entre les logiciels d’un environnement pour favoriser la collaboration et fluidifier la circulation des informations. Parmi plusieurs technologies employées, ceci est principalement rendu possible grâce à l’implémentation du format XML.
Ballmer ajoute que «dans ce secteur, les plus grands gains de productivité sont obtenus lorsque l’on est en mesure de mieux exploiter le travail effectué par d’autres personnes. XML est la clé. XML permettra à toute application de commencer à être exploitée intelligemment par d’autres applications XML de la bonne manière.»51
En prenant ceci en considération, est-il possible que le futur de Microsoft Word en 2006 / 2007 ne repose que sur du «fatras» qualifié de «brouillon» comme cela a été indiqué dans les échanges de courriels lors du traitement de la demande de création d’une norme ISO pour la modélisation Office Open XML?
Pour répondre à cette question, nous émettons ici une hypothèse que nous ne pourrons vérifier faute d’accès au code source et à la documentation des modèles textuels de MSWord antérieurs à WordprocessingML. Notre hypothèse est que l’entreprise Microsoft s’est vue contrainte par la nécessité de produire un schéma qui assure la préservation des documents produits sous MSWord avec le format DOC. Tandis que du côté du concurrent direct de MSWord, OpenOffice, cette difficulté ne se pose pas puisque le format XML a été employé comme pivot de la structuration des éléments dès le début. Le passage à la norme ODF assure alors, pour Sun Microsytems, la rétrocompatibilité avec les anciens documents produits avec OpenOffice. Il y a donc une urgence pour Microsoft de produire une norme «équivalente» à celle de la concurrence qui puisse assurer que les documents au format DOC soient toujours interprétables avec la nouvelle structure implémentée dans les nouvelles versions du logiciel52. Pour étayer notre hypothèse, nous nous appuyons sur le fait que les auteurs de la proposition de la norme justifient leur démarche auprès de l’ISO par l’un de leurs objectifs qui «est d’assurer la conservation à long terme de documents créés durant les deux dernières décennies par des programmes qui deviennent incompatibles avec les nouveautés continues dans le domaine des technologies de l’information»53. Comme nous l’avons vu, à partir de 1994 et jusqu’à l’arrivée de la norme ODF, MSWord et le format DOC représentent la majorité (90%) des parts du marché.
Si Microsoft n’avait pas assuré de continuité entre DOC et DOCX de 2003 à 2007, tous les documents créés avec MSWord pendant les années qui ont précédé cette période charnière n’auraient plus été interprétables par les logiciels de traitement de texte qui lui ont succédé (à partir de la version de 2007 de MSWord). Comme nous l’avons vu précédemment, au début des années 1980, MicroPro International, l’entreprise de S. Rubinstein, a commis une erreur tragique pour l’entreprise et ses logiciels en ne garantissant pas la continuité entre le logiciel WordStar et son successeur WordStar2000. Pour Rubinstein, cette action leur a coûté leurs parts du marché des logiciels de traitement de texte et a précipité la fin de WordStar. À partir de cet antécédent, nous supposons que Microsoft n’a pas voulu reproduire l’erreur commise par MicroPro International.
Si nous revenons légèrement en arrière dans le temps, le succès de MSWord (et plus largement celui de Microsoft) à la fin des années 1980 et au début des années 1990 repose principalement sur l’intégration de composants graphiques dans l’interface, et sur le mode WYSIWYG de son logiciel de traitement de texte, ce même mode qui permettait de produire des «documents parfaits». La structuration des informations était alors axée sur un paradigme graphique et imprimé, centré sur l’objet page, et non sur une structuration textuelle fine des informations dans le document en vue de son partage. Cependant, avec la modélisation du texte et des informations en XML, les documents produits avec des logiciels de traitement de texte ne doivent plus seulement être imprimés, mais également être interprétés voire transformés par d’autres logiciels de l’environnement numérique. La firme Microsoft s’est alors retrouvée dans la situation où devaient coexister ces deux visions du document dans un même schéma afin de garantir à la fois la «préservation» et l’«interopérabilité» des documents produits avec son logiciel depuis les années 1980.
En dépit de cette difficulté à surmonter, le résultat de la conjugaison de ces deux visions du document se concrétise alors dans la norme Office Open XML et son application WordprocessingML pour le logiciel MSWord. Pour réaliser cette transition, Microsoft ne se serait alors pas appuyé sur une définition des concepts mobilisés dans son schéma proche d’autres standards, comme le HTML dont s’inspire ODF (Roig & Ribera, 2021), mais sur une représentation de ces concepts qui correspond à la vision que Microsoft porte sur le document depuis ses débuts: une vision graphique du document imprimé.
Les éléments structurels sont alors définis pour rendre compte et décrire ces mêmes éléments sous leur forme visuelle. L’exemple du paragraphe illustre cette hypothèse. Précédemment, nous avons vu que la notion de paragraphe dans WordprocessingML ne ressemblait pas à ce que l’on attend usuellement d’un tel objet.
<w:p>
<w:pPr>
<w:pStyle w:val="Normal" />
<w:rPr>
<w:b />
<w:b />
<w:bCs />
</w:rPr>
</w:pPr>
<w:r>
<w:rPr>
<w:b />
<w:bCs />
</w:rPr>
<w:t>Introduction</w:t>
</w:r>
</w:p>Le paragraphe n’est plus une subdivision d’un ensemble plus grand, comme un chapitre ou une section plus petite, mais est un conteneur hors de ce type de structuration qui délimite un espace dans la page de MSWord. Dans son modèle textuel, Microsoft décrit les éléments tels qu’ils existent graphiquement dans la page. Le paragraphe de WordprocessingML, en tant qu’incarnation textuelle d’un bloc contenant tous les éléments nécessaires à l’affichage du texte dans la page, peut alors prendre plusieurs valeurs comme un “titre de niveau 1” ou la valeur “Normal” qui, elles, renvoient à la subdivision que nous employons plus généralement pour définir le paragraphe. Microsoft a ainsi donné un autre sens et une autre matérialité au concept de paragraphe: il s’agit de l’unité documentaire dans le modèle textuel de MSWord.
Selon cette perspective, le sens donné précédemment à l’exemple ci-dessus prend alors une autre tournure puisque le paragraphe devient un objet contenant des propriétés descriptives et des propriétés exécuter, c’est-à-dire à afficher sur la page54.
En créant ce modèle pour faire une passerelle entre les formats DOC et DOCX, Microsoft aurait également préservé une partie de la vision du document portée par l’entreprise à ses débuts dans les années 1980. Cet héritage issu d’une première modélisation propriétaire du document se retrouve aujourd’hui dans la norme Office Open XML et son application WordprocessingML.
De cette manière, nous avons la possibilité d’examiner à la fois ce que le modèle décrit, ainsi que d’observer si la représentation graphique associée correspond à la définition du modèle. Comme nous le voyons pour certains éléments, par exemple les métadonnées, le modèle du document ne rend pas compte de tout ce qu’il est possible d’y inscrire: certains éléments n’y sont pas décrits et ne peuvent donc pas exister dans le document. Cependant, puisque les auteurs sont dans une interface WYSIWYG, ils ont recours à une structuration uniquement graphique de ces éléments qui ne peuvent pas être décrits par le modèle. Là où d’autres environnements d’écriture sont plus stricts et ne permettent pas d’y inscrire des informations non décrites dans le modèle, par exemple le XML, l’environnement MSWord se trouve être plus permissif, car il permet aux auteurs de ne plus s’en remettre au modèle textuel pour écrire, mais uniquement à une structuration graphique des informations dans le texte. Cette capacité que donne MSWord aux utilisateurs – et plus largement le traitement de texte en WYSIWYG ou tout autre modèle plus permissif – de jongler entre les paradigmes selon ce que le modèle permet d’écrire donne à la fois de la souplesse en termes d’écriture, si l’on indique au lecteur de s’en remettre à une littératie de la page, mais génère aussi le risque que les calculs effectués sur le texte produisent un sens différent de celui souhaité, sous réserve d’une intervention manuelle pour restructurer les informations.
Conclusion
Dans ce premier chapitre de la deuxième partie de la thèse, intitulé «Écriture numérique: production», nous avons analysé la production du sens dans les documents envoyés par les auteurs des textes de l’ouvrage Contributions numériques: cultures et savoirs, rédigés dans l’environnement Microsoft Word. À partir du postulat développé dans la première partie de la thèse, selon lequel l’écriture est un phénomène distribué entre toutes les entités présentes dans son environnement, qu’elles soient sociales, techniques, humaines ou non humaines, nous nous sommes interrogés sur le sens produit par l’environnement MSWord dans sa dimension technique. L’hypothèse que nous avons émise est que le sens ainsi produit dépend non seulement des médiations techniques qui constituent cet environnement, mais également de toute son histoire dont héritent les versions du logiciel employées par les auteurs.
Pour répondre à cette problématique et étayer notre hypothèse, nous avons structuré ce chapitre en trois sections. Dans la première, nous avons décompressé et analysé les textes de Contribution numérique afin de comprendre ce que MSWord inscrit dans le document. En nous concentrant principalement sur les couches les plus hautes de cet environnement, nous avons examiné la modélisation des informations dans les documents étudiés, c’est-à-dire le modèle textuel de MSWord afféré à son format DOCX. À l’intérieur de cette modélisation, qui ne présente pas de majeure différence entre les versions mobilisées dans cette étude, nous nous sommes aperçus que les concepts qui définissent la structure des informations réfèrent à des objets graphiques. En ce sens, ces concepts oscillent entre deux représentations: la représentation textuelle (en WordprocessingML), censée rendre le contenu interopérable avec d’autres environnements numériques et son pendant graphique affiché dans une page. Pour comprendre d’où vient cette vision graphique du document, une deuxième section de ce chapitre concerne l’histoire des logiciels de traitement de texte dans laquelle s’inscrit MSWord, dont la première version remonte à 1983. Pendant environ deux décennies, des années 1970 au début des années 1990, des entreprises et des institutions réalisent un certains nombres d’avancées technologiques dans le domaine de l’écriture numérique, notamment Xerox, Apple, Microsoft, MicroPro International, SUN Microsystems, des professeurs de l’université de Stanford, etc, et orientent ces développements à des fins d’impression des documents, avec pour objectif l’obtention d’un document «parfait». Le document «parfait» est un document qui ressemble trait pour trait à ce que l’écran affiche, d’où l’engouement pour le mode WYSIWYG autour duquel se construit MSWord. En parallèle de ces développements, des modèles standards, formels et explicites de structuration des contenus apparaissent à la fin des années 1980 et surtout dans les années 1990, tandis que la plupart des environnements d’écriture fonctionnent alors en silos fermés. La question de l’interopérabilité entre les environnements numériques est alors posée à différentes échelles micro et macro, de l’échelle individuelle à l’échelle internationale. À l’occasion de cette problématique, nous rappelons dans une troisième section du chapitre le changement de modélisation du texte dans l’environnement MSWord lors de l’intégration de la technologie XML et du passage du format DOC au format DOCX. Pour Microsoft, ce changement de modèle abouti par le dépôt d’une norme ISO (29500) et à son implémentation sous la forme du schéma WordprocessingML que nous avons analysé dans la première section du chapitre. Lors de cette transition de DOC vers DOCX, Microsoft s’est retrouvé face à la nécessité de devoir préserver une forme de compatibilité avec les anciens documents produits sous le format DOC et garantir leur pérennité auprès des utilisateurs. Ce faisant, nous avons émis l’hypothèse que Microsoft a préservé dans le format DOCX une part de la vision du document tel qu’il était conçu sous le format DOC.
Le format DOCX oscille alors entre deux paradigmes. D’une par un paradigme formel et explicite des éléments textuels, grâce entre autres à l’emploi d’un schéma et à leur description textuelle, et d’autre part, un paradigme graphique hérité des premières versions du logiciel, lorsque la finalité du document était l’impression. Ce deuxième paradigme est accentué par le mode WYSIWYG et l’affichage à l’écran de la page, qui reproduit de manière fidèle celle qui sera imprimée. Le document dans MSWord renvoi alors à deux types d’interprétation possible: la première relève de la page imprimée, tandis que la deuxième relève d’une structure propre à l’environnement numérique, lisible à la fois par la machine et par les êtres humains.
En conséquence, la production du sens dans cet environnement d’écriture dépend du positionnement de l’auteur et de la littératie qu’il convoque, numérique ou imprimé. La tentative de Microsoft de concilier ces deux modes d’écriture dans un seul environnement s’avère alors fonctionnelle puisque le logiciel le rend réalisable, mais laisse également la possibilité aux utilisateurs de ne se référer qu’à un seul de ces paradigmes. Le choix de l’un ou l’autre de ces modes d’écriture n’étant pas explicite rend alors confus la lecture si l’on ne sait pas à quelle littératie le document renvoie, surtout lorsque la lecture est réalisée par un autre programme de l’environnement numérique. Lorsque le document produit se réfère au paradigme graphique de la page, la structuration des éléments n’est plus forcément explicite et peut occasionner des erreurs de transformation – qui n’en sont pas du point de vue computationnel – que seul une action humaine pourra corriger ou rectifier.
Au prisme de cette analyse, nous développerons par la suite le fait que l’environnement MSWord n’est pas conçu pour écrire des documents que l’on peut transformer sans ambiguïté en un autre type de document. Comme nous le verrons dans la partie suivante de cette thèse, lors de la transformation de ces documents en objets publiables, la première étape consiste à écraser tous les styles appliqués au texte (que cette étape soit automatique ou manuelle) et cela que l’on utilise la suite Adobe avec InDesign, un logiciel de transformation comme Pandoc, ou encore des chaînes éditoriale comme Numerev, Métopes ou encore Lodel.
Bibliographie
Comme nous l’avons vu dans le deuxième chapitre, l’emploi du terme lecture est à double sens. Ce mot désigne les actions de lire et d’interpréter dont les êtres humains sont capables, tandis que la lecture du côté des ordinateurs relève plus de l’action de scan d’une tête de lecture qui lit une donnée pour effectuer des calculs, comme le désignait Turing dans sa machine (Turing, 1936).↩︎
Les premiers logiciels de traitement de texte comportaient leur propre format et leur propre syntaxe de structuration des contenus. Ce faisant, les documents ne pouvaient pas être portés d’un logiciel à un autre, voire d’une version d’un logiciel à une autre.↩︎
Nous n’évoquons ici que les formats pour liés à du texte, mais tous les objets qui peuvent être numérisés font l’objet d’un encodage dans des formats.↩︎
Nous faisons une distinction entre une phase de production d’un document et une phase de transformation à des fins de diffusion de ce dernier, ces deux phases appartenant alors à l’ensemble que l’on nomme écriture numérique.↩︎
Nous le nommerons dorénavant Contribution numérique.↩︎
Le Pressoir est une chaîne éditoriale multimodale avec pour objet principal une version web augmentée. Cette chaîne est développée par la Chaire de recherche du Canada sur les écritures numériques, en partenariat avec le CRIHN (Centre de recherche interuniversitaire sur les humanités numériques) et l’université Paris 8. Voir la page web du Pressoir: https://ecrinum.gitpages.huma-num.fr/pressoir/, consultée le 11 décembre 2024.↩︎
L’étude menée par Roig et Ribera consiste en une étude comparative des documents produits selon la norme de Microsoft, Office Open XML, avec les documents produits selon la norme Open Document Format. Ils décompressent les documents pour accéder aux différents fichiers sources en XML qui le composent.↩︎
La forme décompressée en XML est également graphique, de même que toutes les formes textuelles. Nous employons ici formes graphique et textuelle pour distinguer le texte dans l’interface de traitement de texte et le texte dans sa forme brute.↩︎
Pour décompresser un document au format DOCX, il suffit de modifier l’extension du fichier en remplaçant
docxparzipet de décompresser l’archive. À l’intérieur de ce dossier, nous y trouvons une bonne douzaine de documents au format XML contenant soit les notes de bas de page, soit les commentaires, soit le contenu du document, etc.↩︎Une partie de la documentation du schéma de WordprocessingML se trouve sur le site web de Microsoft: https://learn.microsoft.com/en-us/office/open-xml/word/structure-of-a-wordprocessingml-document?tabs=cs, consulté le 20 décembre 2024.↩︎
Voir la page de documentation dédiée à l’élément paragraphe: https://learn.microsoft.com/en-us/dotnet/api/documentformat.openxml.wordprocessing.paragraph?view=openxml-3.0.1, consultée le 20 décembre 2024.↩︎
Attention, comme nous le verrons plus loin, la notion de paragraphe comporte un double sens dans MSWord: elle désigne soit le paragraphe en tant que conteneur dans le modèle textuel, soit un paragraphe dans son sens le plus courant, c’est-à-dire une subdivision d’un texte. Dans ce cas-ci, la valeur “Normal” appliqué à l’élément paragraphe de MSWord renvoie au paragraphe comme subdivision.↩︎
Cet élément apparaît en 2007 dans MSWord et est normalement appliqué à des caractères décrits comme complexes dans la documentation, voir la page : https://learn.microsoft.com/en-us/dotnet/api/documentformat.openxml.wordprocessing.boldcomplexscript?view=openxml-3.0.1, visitée le 22 décembre 2024.↩︎
Le texte correspond au texte affiché à l’écran, il est désigné de façon très générique par “texte” du “paragraphe”, et on lui applique une valeur qui correspond quant à elle au niveau structurel du texte, que ce soit un niveau de titre ou un paragraphe.↩︎
Voir la documentation concernée : https://learn.microsoft.com/en-us/dotnet/api/documentformat.openxml.wordprocessing.paragraph?view=openxml-3.0.1, consultée le 22 décembre 2024.↩︎
Les commentaires ont été apportés aux fichiers DOCX depuis LibreOffice. Travaillant uniquement avec des systèmes d’exploitation Unix, je préfère travailler avec des logiciels libres plutôt que propriétaires.↩︎
Un autre environnement de traitement de texte a été développé en 1982 pour répondre exclusivement aux besoins académiques. Il s’agit du logiciel Nota Bene. Ce logiciel connaît encore un grand succès auprès de la communauté américaine et comprend des éléments dans son modèle que l’on ne retrouve pas dans MSWord, notamment les appareils critiques. Voir le site web : https://www.notabene.com/index.html, consulté le 22 décembre 2024.↩︎
À ce sujet, un article du portail web Open Source Observatory de la Commission européenne, mis en place pour partager des ressources et connaissances sur les questions d’interopérabilité en Europe, nous indique qu’aucun autre logiciel, à leur connaissance, n’utilise la modélisation du texte employée pour le format DOCX. Voir la page web: https://interoperable-europe.ec.europa.eu/collection/open-source-observatory-osor/document/complex-singularity-versus-openness, consultée le 11 janvier 2025.↩︎
Voir la page web: https://history-computer.com/technology/the-history-of-harvard-mark-1/ consultée le 16 décembre 2024.↩︎
Nous avons vu dans le deuxième chapitre que des fabricants comme Olivetti fabriquent de nouveaux modèles à la fin des années 1960.↩︎
Voir la documentation d’Electric Pencil publiée en 1977 : https://www.sol20.org/manuals/pencil.pdf, consultée le 18 décembre 2024.↩︎
Toutes ces fonctions sont décrites dans le TeXBook, le manuel de référence écrit par Knuth. C’est un incontournable pour qui souhaite en savoir plus la conception d’un document dans TeX. Il est disponible en version numérique sur le dépôt du CTAN (Comprehensive TeX Archive Network). Voir la page web https://mirrors.ircam.fr/pub/CTAN/systems/knuth/dist/tex/texbook.tex, consultée le 18 décembre 2024.↩︎
Voir la page du CTAN: https://ctan.org/, consultée le 11 janvier 2025.↩︎
EasyWriter est le logiciel développé pour Apple. Il a été très mal noté du fait de sa non portabilité sur d’autres ordinateurs qui n’étaient pas issus de la firme Apple puisqu’ils utilisaient un format de support qui n’était pas compatible avec les autres systèmes (Bergin, 2006a).↩︎
Traduction personnelle de: «from the outset, my concept was of a front office type of suite of products. It was called Starburst, and it contained CalcStar, InfoStar, and WordStar: the spreadsheet, the database, and the word processor.»↩︎
Selon les propos de Rubinstein: «WordStar was the first program that could show on-screen where the page breaks would fall» (Rubinstein, 2006)↩︎
Voir la citation de Bob Taylor, d’abord directeur de l’ARPA de 1965 à 1969 puis fondateur du Xerox PARC, dans Dream Machine : «I don’t think that Ivan, or I, or anyone who’s been in that ARPA position since, has had the vision that Lick had. Most of the significant advances in computer technology – included the work that my group did at Xerox PARC – were simply extrapolations of Lick’s vision. They were not really new visions of their own. So he was really the father of it all». (Waldrop, 2001, p. 470)↩︎
Dans une interview de Charles Simonyi organisée par le Computer History Museum en 2008, Simonyi atteste l’emploi du terme WYSIWYG en 1975 avec la version 3.1 du logiciel Bravo, voir l’entretien, p.21 : https://archive.computerhistory.org/resources/access/text/2015/06/102702232-05-01-acc.pdf↩︎
Ce fait est contesté par Rubinstein, comme nous l’avons vu précédemment avec son logiciel Wordstar. Pourtant, Bergin semble avoir trouvé des traces de cet acronyme dans les compte-rendus du projet Bravo (Bergin, 2006b)↩︎
Traduction personnelle : «If you compare the hardcopy of your document with Bravo’s display, you will see that although the text is identical, the hardcopy has more words on each line, so that the two versions look quite different. In order to see a nearly exact facsimile of the hardcopy on the screen, you can give the command
Look hardcopy (note the lower-case h). You are now in hardcopy mode on the screen. Until further instructed, Bravo will represent the printed version of your document as faithfully as it can, by positioning each character on the screen within one-half screen dot (about .007 inches) of its position in the final hardcopy.» voir le PDF à cette URL: https://xeroxalto.computerhistory.org/_cd8_/altodocs/.bravomanual.press!2.pdf, consultée le 29 décembre 2024.↩︎Le PARC n’a pas tout inventé. Beaucoup de recherches ont été menées dans d’autres centres de recherche et ont été implémentées dans les ordinateurs plus ou moins pendant les mêmes années. Le PARC réutilise d’ailleurs les recherches réalisées à l’Université de Stanford, notamment la souris qu’a développé Douglad Engelbart et ses équipes de recherche dans les années 1960. La demande de brevet pour cette technologie a d’ailleurs été déposée en 1967 et obtenue en 1970, voir le document publié par l’office des brevets des États-Unis https://patentimages.storage.googleapis.com/7d/13/7e/3fd1de4c37ed12/US3541541.pdf, consulté le 20 janvier 2025. Si le PARC récupère ces technologies, c’est parce qu’une partie des membres travaillant avec Engelbart sont ensuite allés travailler au PARC.↩︎
On peut lire dans l’interview de Simonyi précédemment citée, un passage racontant une discussion avec Steve Jobs datant de 1983: «“Oh now I’ve got to show you the crown jewels, this is like top, top, top, top, top, top, secret” and then he shows us or draws us actually, I don’t think it was even in the, just draws us a drop-down menu, and you know, we were kind of sitting there and we said, “Oh yeah, Steve,
that’s very nice.” Of course, we knew everything about dropdown menus. I mean I’ve seen drop-down menus for ten years by that time. I’m sure it must have been shocking for everybody else, but for us, you know, you kind of forgot that, and he tends to forget that we all came from the same roots, and some of us were more intimate with the roots than others, but at the same time, you know, he always tells Bill that how Bill stole Mac and then Bill says, “No, no, no, we both stole the same, you know, we both stole the Xerox thing.”»↩︎ Nous passons très rapidement sur le logiciel WordPerfect, car il n’apporte rien de plus significatif à cette étude. Néanmoins, nous avons noté que Kittler l’utilise comme exemple dans sa présentation intitulée Le logiciel n’existe pas publiée en 1992 qu’il rédige avec ce logiciel pour définir la caractéristique exécutable des mots dans l’espace numérique: «Le sigle WP fait en effet ce qu’il dit. Contrairement non seulement au mot “WordPerfect”, mais aussi aux mots vides de la vieille Europe tels que “Esprit” ou “Mot”, les fichiers informatiques exécutables incluent tous les sous-programmes et les données nécessaires à leur réalisation. L’acte d’écriture consistant à frapper les touches W et P puis “Entrée” d’une console AT ne rend certes pas le mot parfait mais lance l’exécution de WordPerfect» (Kittler, 2015, p. 34). Dans ce cas-ci WordPerfect incarne cette caractéristique exécutable où le mot ne renvoie plus à une définition des mots le composant, mais à un ensemble de programme qu’il appelle.↩︎
McWilliams résume cette idée comme suit : «After all this processing of words has taken place, the word processing computer will print out as many copies as you like, letter perfect», passage de (McWilliams, 1983, p. 23) cité par (Kirschenbaum, 2016, p. 36).↩︎
La première version de ce standard ECMA, a été déposée en décembre 2006 et approuvée norme ISO 29500 en août 2008. Voir la page web : https://ecma-international.org/publications-and-standards/standards/ecma-376/, consultée le 06 janvier 2025.↩︎
En France par exemple, la première version de 2009 du référentiel général de l’interopérabilité recommande l’utilisation des normes ODF ou OOXML, voir https://www.numerique.gouv.fr/uploads/Referentiel_General_Interoperabilite_V1.pdf, consultée le 06 janvier 2025.↩︎
Sun Microsystems, l’entreprise qui développe la suite OpenOffice, soumets la demande de création de la norme OpenDocument Format à l’Organization for the Advancement of Structured Information Standards (OASIS), qui l’approuve en mai 2005, voir https://www.oasis-open.org/standards/, page consultée le 06 janvier 2024. Elle sera ensuite approuvée par l’ISO et publiée en décembre 2006 sous le numéro 26300 pour devenir une norme internationale, voir https://www.iso.org/standard/43485.html, page consultée le 06 janvier 2024.↩︎
En 2021 Roig et Ribera (2021) mènent une étude comparative entre ODF, la norme Open Document Format, et OOXML, la norme de Microsoft. Il en ressort un manque de clarté dans la norme de Microsoft, à la fois en termes de structuration des informations qu’en termes de technologies mobilisées pour décrire certains éléments complexes tels que les graphiques, tandis que la norme ODF mobilise des standards partagés par d’autres environnements. Par exemple, pour insérer des graphiques dans un document, ODF s’appuie sur le format SVG (Scalable Vector Graphics), tandis que Microsoft a intégré sa propre technologie DrawingML pour réaliser la même chose.↩︎
«L’approbation exige une majorité des 2/3 (66,66 %) des votes exprimés par les membres participants de l’ISO/IEC JTC 1. Les votes négatifs ne doivent pas dépasser le quart (25 %) du nombre total des votes exprimés par les comités membres nationaux. Aucun de ces critères n’a été rempli, avec 53 % de votes positifs des membres participants de l’ISO/IEC JTC 1 et 26 % de votes nationaux négatifs.», voir la page web de l’ISO: https://www.iso.org/fr/news/2007/09/Ref1070.html, consultée le 06 janvier 2025.↩︎
Le nombre de ces commentaires sur le dossier ISO 29500 a été ramené à 1100 après une première phase de tri effectuée par des experts, notamment pour éliminer les doublons.↩︎
Voir la page web de l’ISO : https://www.iso.org/fr/news/2008/03/Ref1117.html, consultée le 07 janvier 2025.↩︎
voir la page web de l’ISO : https://www.iso.org/fr/news/2008/02/Ref1114.html, consultée le 07 janvier 2025.↩︎
Voir la page web de l’ISO : https://www.iso.org/fr/news/2008/04/Ref1123.html, consultée le 07 janvier 2025.↩︎
Voir les spécifications XML sur le site web du W3C: https://www.w3.org/TR/WD-xml-970807.html, consulté le 07 janvier 2025.↩︎
L’acronyme SUN du nom de Sun Microsystems créée en 1982 signifie Stanford University Network. L’université de Stanford se situe à Palo Alto, non loin du Xerox PARC. C’est également dans cette université qu’a travaillé le mathématicien et informaticien Donald Knuth, auteur de TeX, ainsi que Douglas Engelbart, l’inventeur de la souris. Bosak n’a pas été étudiant à Stanford, mais il est assez intéressant de noter qu’au cours des dernières décennies du XXe siècle, alors que le sujet de l’écriture sur ordinateur intéresse une grande partie du monde, plusieurs avancées technologiques majeures sont situées dans cette ville.↩︎
Traduction personnelle de : «XML was developed by an XML Working Group (originally known as the SGML Editorial Review Board) formed under the auspices of the World Wide Web Consortium (W3C) in 1996 and chaired by Jon Bosak of Sun Microsystems […] This specification was prepared and approved for publication by the W3C XML Working Group (WG). WG approval of this specification does not necessarily imply that all WG members voted for its approval. At the time it approved this specification, the XML WG comprised the following members: Jon Bosak, Sun (Chair); James Clark (Technical Lead); Tim Bray, Textuality and Netscape (XML Co-editor); Jean Paoli, Microsoft (XML Co-editor); C. M. Sperberg-McQueen, U. of Ill. (XML Co-editor); Steve DeRose, INSO; Dave Hollander, HP; Eliot Kimber, Highland; Tom Magliery, NCSA; Eve Maler, ArborText; Murray Maloney, Grif; Peter Sharpe, SoftQuad;», voir lien précédent.↩︎
Voir la note de remise aux fabricants sur le site web de Microsoft datant du 19 août 2003: https://news.microsoft.com/2003/08/19/core-microsoft-office-system-products-are-complete-released-to-manufacturers/, consulté le 07 janvier 2025.↩︎
Traduction personnelle de: «Support for XML and other industry standards enables seamless communication between Microsoft Office programs and applications from independent software vendors, and lays a foundation for the addition of real-time data and Web services for even greater business value. Improvements in Outlook, Exchange, Windows® SharePoint Services and SharePoint Portal Server provide new capabilities, making it as efficient as possible for individuals, teams and organizations to collaborate».↩︎
Le discours de Steve Ballmer a été retranscrit et est accessible sur le site web de Microsoft : https://news.microsoft.com/2003/10/21/steve-ballmer-speech-transcript-microsoft-office-system-launch/, consulté le 07 janvier 2025.↩︎
Traduction personnelle de: «It is not, from our perspective, a spreadsheet and a word processor. That may be kind of where people think it grew up. We think of Microsoft Office as the foundation for the definitive set of tools that we need to provide to enhance information worker productivity. […] We made some enhancements for collaboration. We extended their Internet capabilities. We made them easier to deploy. But this is really the first generation in a long time where we significantly, I think, advanced the frontier of productivity for the information worker. The Microsoft Office System 2003 is not just a word processor and a spreadsheet. In fact, it’s not even just a client-side application. It’s client-side application that can talk and intelligently exploit server infrastructure, services that run out in the Internet cloud and solutions that have been developed and written by partners of ours as well as by end customers that help enhance the overall productivity experience for people».↩︎
Traduction personnelle de : «The biggest productivity enhancements in this industry come when you’re able to better leverage work that other people have done. XML is the key. XML will allow any application to start getting leveraged intelligently by other XML applications in the right way.» Voir le discours de Ballmer lors du lancement de Office 2003 cité précédemment: https://news.microsoft.com/2003/10/21/steve-ballmer-speech-transcript-microsoft-office-system-launch/.↩︎
En un sens cette préservation des documents est déjà assurée puisque Microsoft a implémenté XML dans MSWord dès 2003. Seulement cette implémentation n’est pas conforme à la norme Open Document Format en vigueur deux ans plus tard.↩︎
Voir la page de l’ISO: https://www.iso.org/fr/news/2007/09/Ref1070.html, consultée le 07 janvier 2025.↩︎
Le sens donné par MSWord au bloc de code signifie que le texte (
<w:t>) “Introduction” est affiché (<w:r>) en gras (<w:b />,<w:bCs />) dans un conteneur de type paragraphe (<w:p>) avec pour propriétés (<w:pPr>) une valeur “Normal” (<w:pStyle w:val="Normal" />) et des styles en gras (<w:b />,<w:bCs />).↩︎