Contexte
Ce billet permet de documenter un ensemble de procédures et de questions en cours de réflexion.
Nous travaillons, avec l’équipe des Ateliers de sens public, à l’édition d’un nouvel ouvrage dont l’objet rend compte d’un événement qui s’est tenu en juillet 2022.
Cet événement a pour thématique les contributions sur les plateformes en ligne et certaines présentations lors de ce forum ont fait l’objet d’un approfondissement à l’occasion de ce livre.
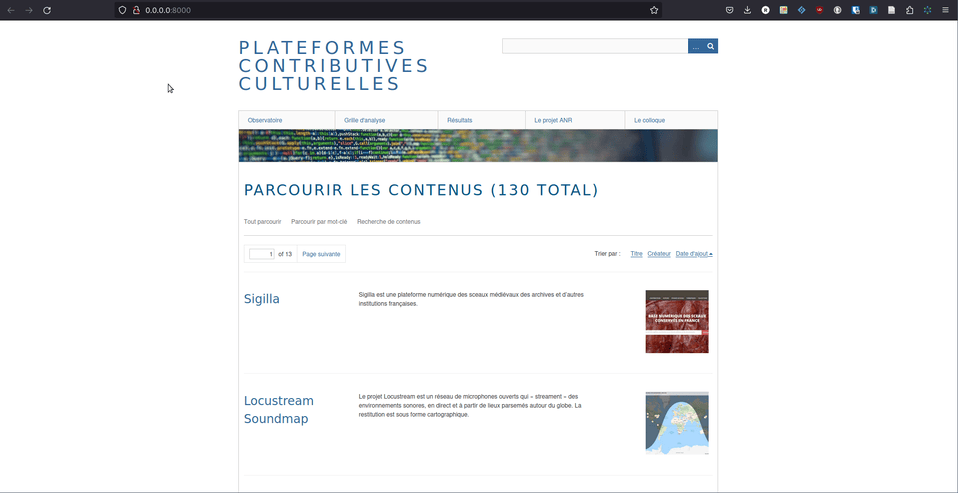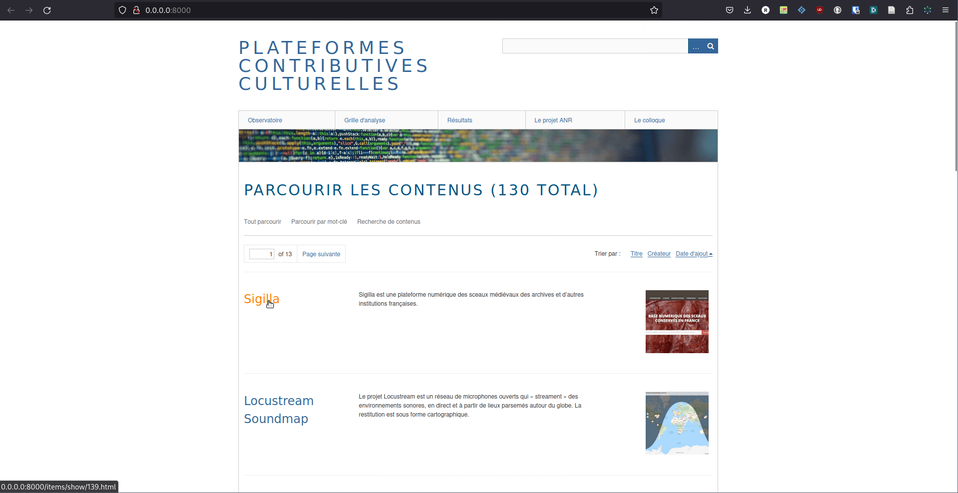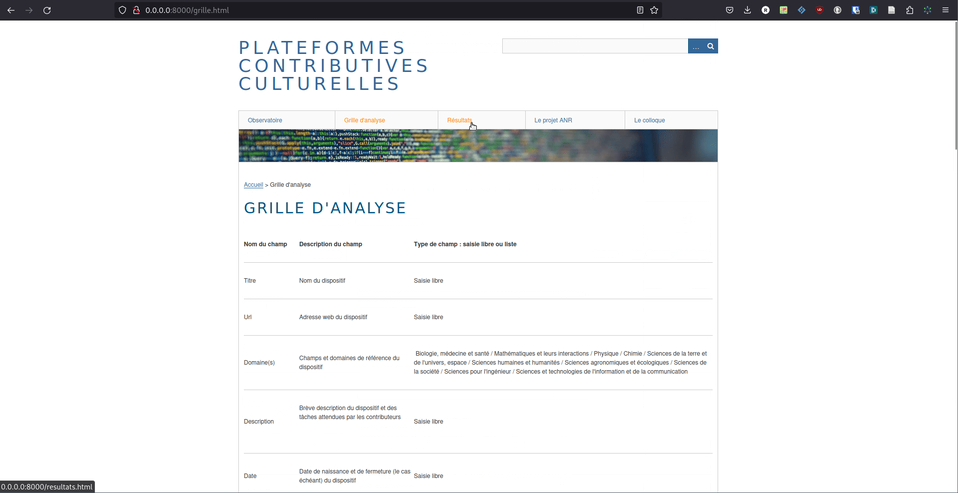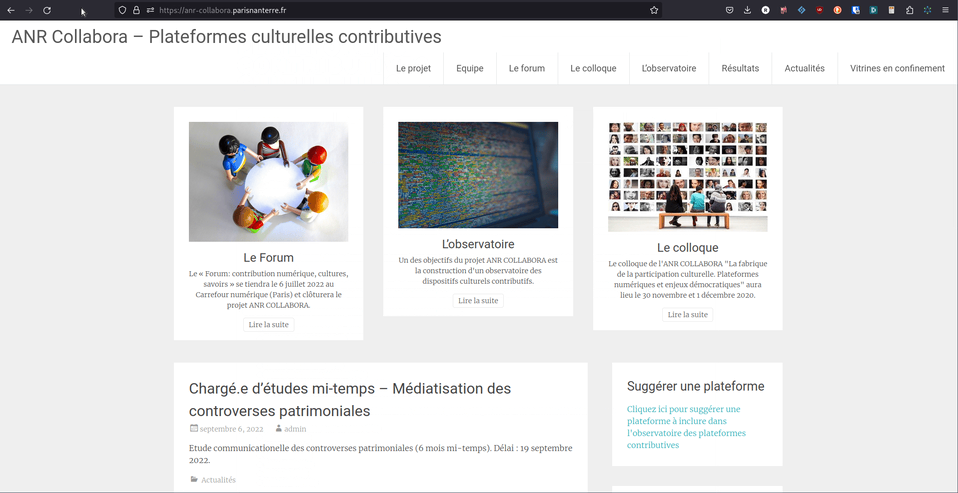
Parmi celles-ci, un chapitre porte sur un projet de recherche dont les données repose sur un site web distribué via le CMS Omeka classic, voué à disparaître prochainement.
Les questions éditoriales autour de ce billet relèvent des informations additionnelles que l’on peut insérer dans ce livre/chapitre.
Essais pour intégrer les données
Les livres web produits avec le Pressoir permettent d’intégrer tout un ensemble d’objets (qui peuvent exister dans l’écosystème du web).
Du coup, on a la possibilité d’intégrer les données de recherche dans le livre d’une façon ou d’une autre, selon si l’on y trouve un intérêt éditorial.
Les données peuvent être récupérées au format CSV. Et là on décide de créer un chapitre additionnel au livre pour y insérer toutes ces données en tant que contenus additionnels.
Dans le Pressoir, les contenus additionnels (c’est un objet créé pour le Pressoir) sont contenus dans un document au format Markdown et rédigés avec un ensemble de YAML et de Markdown.
On obtient la forme suivante :
## idUnique
---
title: Un titre
author: Un Nom
credits: Un Nom
autre: etc
---
Du contenu en MarkdownLe premier écueil que l’on rencontre concerne la transformation des données du fichier CSV vers cette forme des contenus additionnels.
L’idée au départ est de faire un petit script en Python pour y arriver. Transformer du CSV en YAML c’est relativement facile, surtout avec la librairie pyYAML.
Pourtant les ennuis commencent déjà : le document CSV généré par Omeka n’est pas des plus propre pour travailler. Par exemple, certaines données contiennent plusieurs valeurs séparées par un simple espace mais chacune des valeurs contient elle-même un sous ensemble de clef : valeur, complexifiant ainsi la structure des données.
Par exemple, les liens vers les réseaux sociaux y sont indexés comme suit :
item_reseaux-sociaux : Facebook : url Instagram : url Twitter : url
Pour rappel, dans la syntaxe YAML, le séparateur entre la clef et la valeur est également le signe :. À cet endroit beaucoup d’erreurs s’insèrent dans le YAML produit.
Il faut aussi faire un gros nettoyage sur les URL qui contiennent toutes les balises HTML <a href=> composée de divers paramètres selon les hyperliens.
Une fois la conversion terminée on se rend alors compte que pyYAML n’écrit pas correctement les caractères spéciaux contenus dans le CSV. Tous les accents y passent sans exception et nous nous retrouvons avec des chaînes de caractères du type \en09 (exemple faux) dans le YAML.
Ce n’est pas un soucis majeur mais il faut quand réinscrire les bons caractères, par exemple avec des expressions régulières.
Arrivé à ce stade eh bien on a juste un document YAML qui contient toutes les données transformées (et c’est pas encore super clean) mais on a pas le fichier Markdown avec la structure présentée ci-dessus.
Là on a plusieurs idées, comme faire un template HTML et passer par Pandoc pour redistribuer toutes les valeurs du YAML dans un nouveau document, encore qu’il faudrait aussi faire ça avec Python, parce que toutes les entrées de chaque ligne du CSV se nomment pareil et qu’il nous faudrait pouvoir boucler sur ces infos pour générer tous les contenus additionnels.
On pourrait aussi repartir du CSV et transformer directement le document en Markdown en appliquant cette dernière méthode et trouver une solution pour dédoublonner les multiples données sur une même entrée.
Toutefois ça commence à faire un peu long pour remplacer des données décrites en Dublin Core et bien indexées dans une base de données sur un Omeka.
L’objectif de cette manipulation transforme donc des données décrites avec un standard perenne en texte brut, sans compter la perte de la mise en page (d’un côté un site web dédié et de l’autre un chapitre perdu à la fin d’un livre).
La question est donc à reposer : s’agit-il d’un geste éditorial dont l’objectif est d’apporter une plus-value au livre ? Ou s’agit-il de trouver une solution pour archiver ces données et les garder accessibles en ligne ?
Tentatives pour archiver le site web
On en vient enfin au titre de ce billet (je ne savais pas comment l’appeler autrement).
En discussion avec Hélène et Nicolas on a donc opté pour faire d’autres tests pour trouver une alternative pour sauver ce site web sans générer de grosses dépenses pour maintenir ou migrer tout le système.
Étant donné que les données du site sont plutôt stables (pas de nouvelle entrée prévue), nous avons eu l’idée de passer le site web en statique et de supprimer la base de données. On ne garderait que les fichiers HTML et on les sert sur un serveur (au prix d’une perte de quelques fonctionnalités) mais au moins on peut tout stabiliser et pérenniser l’accès aux données sans changer l’URL.
Du coup on opte pour passer d’un site dynamique à un site statique. Le meilleur outil pour faire ça est sans nul doute wget.
Je me documente un peu et je trouve un super tutoriel en ligne qui explique les bonnes pratiques avec cette commande et je me lance dans cette (re)quête.
> wget --wait=2 \
--level=inf \
--recursive \
--page-requisites \
--user-agent=Mozilla \
--no-parent \
--convert-links \
--adjust-extension \
--no-clobber \
-e robots=off \
https://bliblablouLes paramètres permettent d’affiner la requête :
waitdemande d’attentre 2secondes entre chaque ressource,levelpermet de régler le niveau de profondeur de récupération des fichiers (iciinfpour infini),recursivespécifie le télwçhargement récursif des éléments,page-requisitesordonne de récupérer les ressources nécessaires au fonctionnement du site web,no-parentinterdit de remonter dans les dossiers parents,convert-linksest très utile et réécrie les liens entre les ressources pour que le site web puisse tourner en local,user-agentspécifie une version particulière dewget,no-clobberpermet de ne pas retélécharger des ressources déjà téléchargées,adjust-extensionsauvegarde les fichiers HTML et CSS avec les bonnes extensions de fichier,e robotspermet de régler l’exclusion de robots.
Sur le papier tout semble aller comme sur des roulettes.
Je teste la commande sur ce carnet et hop ! tout fonctionne parfaitement ! J’ai un site miroir parfait.
Il faut ensuite le tester sur le Omeka, et là ca se corse. Le premier test est effectué dans le train, entre Lyon et Montpellier.
Je lance la commande avec ma 4g hasardeuse et résultat … au bout de 2h de train, j’ai récupéré quelques milliers de fichiers sans arriver au bout de la récolte du site web.
C’est très frustrant parce que je dois éteindre l’ordinateur et descendre du train (pour une fois que le train arrive à l’heure…).
Ce n’est pas grave, ça a l’air de fonctionner, 2h et je ne me suis pas fait virer par le serveur du coup j’ai l’impression que ça va le faire !
Arrivé à destination, j’ouvre l’ordinateur, le branche sur secteur et sur wifi, j’ouvre le terminal et hop je relance ça et je croise fermement les doigts, les poings, les pieds et les orteils pendant que je m’endors en espérant que la nuit portera ses fruits.
Rien du tout. Je me lève le matin et là je vois que ça mouline encore, j’ai récolté plus de 7000 documents dont la plupart sont des fichiers du flux RSS et les données JSON et CSV de l’API…
Je coupe donc tout ça et je le jette à la poubelle.
Je réouvre le manuel de wget et là je tombe sur --reject=LIST, un paramètre permettant de supprimer certaines extensions des téléchargement.
Au départ, l’idée était de reconstruire le plus fidèlement possible une archive statique de ce site web, toutefois je me rends compte qu’il faut faire des choix et que l’archive recréée ne sera peut-être pas complètement identique…
Est-ce qu’il y a un intérêt à garder tous ces jeux de données ou un flux RSS pour un site quasiment figé ?
Dans tous les cas, la commande
> wget --wait=2 \
--level=inf \
--recursive \
--page-requisites \
--user-agent=Mozilla \
--no-parent \
--convert-links \
--adjust-extension \
--no-clobber \
--reject=xml,json,csv,atom,rss,rss2,tmp \
-e robots=off \
https://urlsemble ne plus récupérer ces centaines de documents ! Toutefois la capture du site ne sera pas moins longue dans ces conditions, wget passe quand même sur ces ressources, les télécharge, puis les supprime.
Il me reste un peu moins d’une heure de train pour rentrer à Paris, on va voir ce que j’arrive à récupérer d’ici là.
La commande qui fonctionne
C’était un peu trop ambitieux d’espérer récupérer tout le site web avec la dernière commande en simplement une heure.
Il aura été nécessaire de laisser tourner wget pendant plus de 11h pour récupérer l’intégralité du site web avec la commande suivante :
> wget --wait=1 \
--level=inf \
--recursive \
--page-requisites \
--user-agent=Mozilla \
--no-parent \
--convert-links \
--adjust-extension \
--no-clobber \
--reject=xml,json,csv,atom,rss,rss2,tmp \
-e robots=off \
https://anr-collabora.parisnanterre.fr/observatoire/La différence avec la commande précédente est la réduction du temps d’attente entre chaque requête d’une seconde (wait=1).
On a pu récupérer plus de 11600 fichiers constituant tout le site web ! La plupart des fonctionnalités ont été préservées (recherche par mot-clés ou par tag), le CSS et les images sont bien présents.
Il ne reste plus qu’à supprimer la version existante avec Omeka Classic et déposer l’archive statique sur le serveur pour vérifier que tout fonctionne correctement !